
Machine Learning 2.0.1. - Imbalanced Classification Problems
In my last blogpost I talked about how Supervised Learning can help us to classify newspaper articles. Sadly, this does not always work so great. Let’s remember what we wanted to do with our newspaper article example. We have 500 newspaper articles, which we would like to categorize into 5 different categories: Politics, Economics, Sports, Entertainment and Others. We hand-code 45 of these newspaper articles and feed this information to our machine as training data. The machine then learns from this data to classify the rest of the 450 newspaper articles on its own. There is only one problem with that: Most of machine learning algorithms are based on the assumption that there is a more or less equal distribution of classes in the training data (meaning that we have 10 newspaper articles in each of the 5 categories in our training data). Often, this might not be the case. There might be one dominating class. For example, we might have 20 or 30 newspaper articles in the category “Others”. This is called an Imbalanced Classification Problem.
Imbalanced Classification Problems
The problem with imbalanced classification problems is that the minority class (the class with view observations) is often more important than the majority class (the class with a lot of information). The problem with many algorithms is that they are based on the idea of probabilities. Now, if 90 percent of my 50 newspaper articles belong to the class “Others”, algorithms will read this as a high likelihood of unknown articles to belong to this category and may simply place all of the unknown, new newspaper article, which we have not hand-coded, into this category. The larger one of the categories, the more likely that this will happen. Another problem is that the algorithm will learn more from the majority class, simply due to the fact that it contains more information. And it will learn less from the minority class, simply due to the fact that it contains less data to learn from in the first place. This can then lead to bad predictions for the minority class. Imbalanced learning is still one of the main shortcomings in machine learning and severely limits its reliability. But in real life there are many classification exercises which involve imbalanced classification. Examples are Spam detection or Fraud Detection (for more examples see this blogpost.
Misleading Accuracy
To evaluate Machine Learning algorithms we often look at their accuracy. As an example, we can take our training data (in our case the 50 newspaper articles we hand-coded), split it again into a training and testing dataset (let’s say, 25 newspaper articles each) and feed the training part of the training data into the model. We then tell the model to make predictions for the 25 remaining articles belonging to the testing part of our training data. Through this we can compare the predictions made by the model with our hand-coded categories for these 25 newspaper articles. We might then see that 90 percent of the predictions made by the model coincide with the actual hand-coded categories. This means that accuracy is nothing more or less than the share of correctly predicted data points over the total number of predictions made. There are many other forms to measure a model’s performance, but the Accuracy Measure is still widely used. Now, with Imbalanced Classification Problems the following might happen: 90 percent of our newspaper articles are in the “Other” category. Our algorithm puts all of the new, not hand-coded newspaper articles in the “Other” category. Our accuracy is then 90 percent. Not because the algorithm did such a great job, but due to the fact that nearly all data belongs to this category! This is an example of why we should always carefully evaluate our model’s performance and should not rely on simply one metric. This is especially important for
Help! Dealing with Imbalanced Classification Problems
Okay, now that we understood what an Imbalanced Classification Problem is – how can we deal with it? There are several ways how to handle these kind of problems. But fist of all, it’s recommended that you look at several performance measures instead of just focusing on model accuracy. After detecting the problem, you can then address it through resampling or penalized algorithms as well as through looking at several different algorithms. Let’s have a look at this in more detail.
Using different performance measures
As I mentioned already above, due to misclassification problems but also based on other criteria, it is recommended to look at several model performance measures: Confusion Matrix, Precision, Recall, F1 Score, ROC Curve.
Resampling Techniques
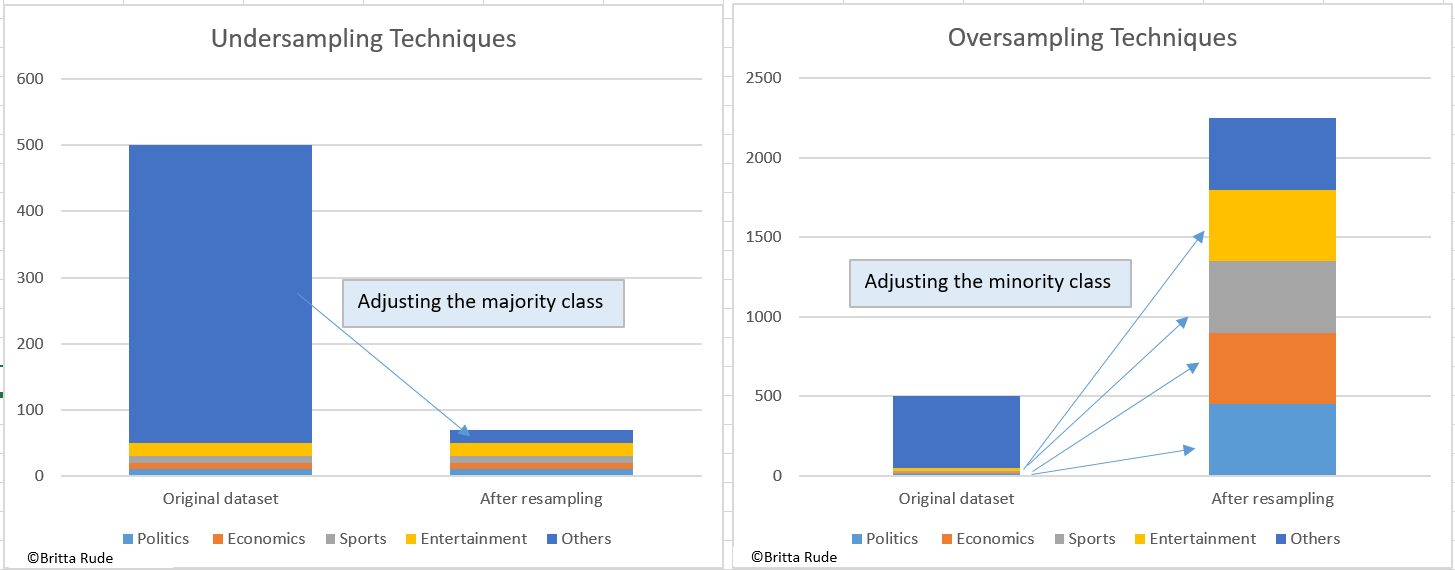
Let’s get back to our newspaper article example. Remember: 90 percent of the newspaper articles belong to the “Other” category, leading to a highly imbalanced dataset. Now, what we can do is simply decrease the size of the majority class by only keeping a subsample of its data. This is called undersampling. Similarly, but the other way around, we can increase the size of the minority class by creating copies of it. This is called oversampling. The downside of this approach is that we might lose valuable information through undersampling and create non-representative datasets. The training data might not mirror the actual underlying overall dataset anymore. If we artificially decrease the “Other” category among our 45 newspaper articles, this might not be in line with the actual set of 500 newspaper articles anymore. Similarly, inflating all other 4 categories decreases the representativeness of our training data of the prediction data. Additionally, undersampling might lead to overfitting. There are several possibilities of under- and oversampling. We can simply create copies of the minority classes (see this example for more details). Alternatively, we can cluster the majority class and remove subsamples of each cluster, as in this summary. Or we can create slightly varying copies of our minority class when doing oversampling. Other methods are called SMOKE, Tomek links or NearMiss. For a summary of undersampling methods see here and for the one on oversampling see here.
Trying out different algorithms
Instead of resampling, you can also try out different algorithms. This is also called Spot-checking different algorithms. When spot-checking algorithms, try to look at different algorithm types, such as instance based methods (e.g. KNN), functions and kernels (e.g. regressions or SVM), rule systems (e.g. a Decision Table) and decision trees (e.g. CART). On Quora, you can find a list of the top algorithms used in 2021.
Penalize your model
Another alternative is to penalize your model for making mistakes on predicting the minority class. Through this you can tell the model to pay more attention to the minority class (Source). One example is the penalized algorithm.
Conclusion
If we face imbalanced classification problems, we have to be creative. As you have seen in this blogposts, there is no short list of how to deal with Imbalanced Classification Problems. The solution you choose will ultimately depend on the structure of your data and the nature of your underlying problem. There is definitely no one-size-fits-all solution here!